One of the things that’s been somewhat difficult to pin down are some of the false activations I’ve been seeing with Myroft / precise. It’s pretty damn good at detecting when I actually say the wake-word, but sometimes it activates at just…the oddest, small sounds, or little blips that sound nothing like it. So, I’ve been doing some digging, and here’s what I found.
First off, precise-collect is a tool within precise that allows the user to very quickly record lots of samples of whatever – wake-words, not-wake-words, or whatever it is you want to record. It’s a nice interface, command-line of course, but it seems to be reasonably fast. However, upong investivating the sound files that it was generating, I disovered a sort of startling number of audio artifacts. Small pops, blips, bloops, would happen about every twenty files or so, and sometimes they’re significant enough that I could easily see where they would end up confusing the learning that precise was attempting to do with them.
Also somewhat less than ideal is that it’s difficult to know when, exactly, to start speaking after you hit the spacebar. In general, I’ve found that there’s more space on the front end of my audio files than I’d like to have using precise-collect, and I suspect that the audio anomalies along with the unintentional silence was contributing to the a lower-quality dataset than I’d like to have. The “dead air” at the front of the files is particularly troublesome, as often the microphone would pick up anything else in the room. This is a pretty inexpensive USB mic that doesn’t have much off-axis rejection to speak of. Of course, I could set up my USB interface and try to get it working with the VM, then keep using precise-collect, but I got thinking: perhaps precise-collect is the wrong tool to bring to this particular problem.
To see why requires understanding that most modern professional audio editing is done looking at the waveform on a screen, in – obviously – a GUI. As a podcaster and long-ago live sound engineer, this is intuitive to me. Visual representation of a waveform makes it easy to see the data in a file without having to listen to it, and this is where precise-collect fails. A command-line utility could make some sense if it had some sort of “threshold” feature wherein it did not start to record until some arbitrary level was reached (defined in, say, decibels), but precise-collect is a simple utility whose purpose is to simply record the audio input into the correct format for precise to start modeling off of.
Now, I do know about the long-abandoned SoX, I considered that as a possibility, and subsequently rejected it. Firstly, SoX has one HELL of an esoteric (read: beginner-unfriendly) command line syntax, and while some searching eventually found me the command that I’d need to input to get SoX to strip silence from the beginning of the file and the end, the man pages are…written like someone wanted to deliberately confuse the user.
Secondly, SoX has an unfortunate habit of corrupting files. I tried twiddling the knobs, and it would still take about a full third of the input files, and output uselessly empty 44 byte (yes, byte) files. No matter how much I adjusted, I could not get it to stop doing this. It might have been easier to troubleshoot this had the man page been useful or there been a website with some support information, but there isn’t. There’s just old Sourceforge posts in miles-long post after post format.
Thirdly, all of this is happening via a command line. There’s no graphical preview for what the output files might look like, which would make adjusting the input parameters far easier. For the reasons I discussed above, audio tools are probably best used via a GUI, because of the intuitive nature of looking at a graphical waveform. If SoX had a graphical frontend, that would make a lot more sense, because command line tools have obvious advantages when it comes to scripting operations for large numbers of files that all need the same thing done to them. But it doesn’t, so even the files that SoX produced that were usable weren’t really, because it would cut off too much or too little of the silence, and I eventually lost patience trying to get this fiddly method to work. Finally, editing hundreds of individual files is a nightmare, even with a GUI. If there’s a way to consolidate all of the files into a cohesive whole and edit THAT, it would be easier, then re-split it. Combined with the audio artifact issue with precise-collect that I simply did not have the time or patience to track down, and this workflow was unacceptable to me.
So, what to do? Well, I came up with a process that seems to be working very well, and allowed me to produce a lot really high-quality wake-word files in a very short amount of time.
For this, I’m using two bits of software: Audacity, which I hope everyone is familiar with, and a new piece of software I found, WavePad.
The process is quite straightforward. First, I record in Audacity. I could do this with my Nice Microphone setup in Logic, but there’s simply no need at the sample rate we’re working with here. Plugging in my USB mic in a quiet room is just fine. Now, I record my wake-word as with precise, except I left a few seconds of silence between each sample, so I end up with a five-minute file of me saying “Computer” in various inflections / distances from the microphone / tones. Not having to record these all as separate instances makes the recording process go very quickly, and I could record a few hundred instances of my wake word in about ten minutes.

Of course, now, because we’re in Audacity, it makes it very easy to see any extraneous noise that needs to be cleaned up, chairs creaking, etc. All of this can be done quickly by looking at the waveform, then exporting the audio. Any other adjustments to the file can be done at this point – de-noising, correcting gain or clipping, etc.
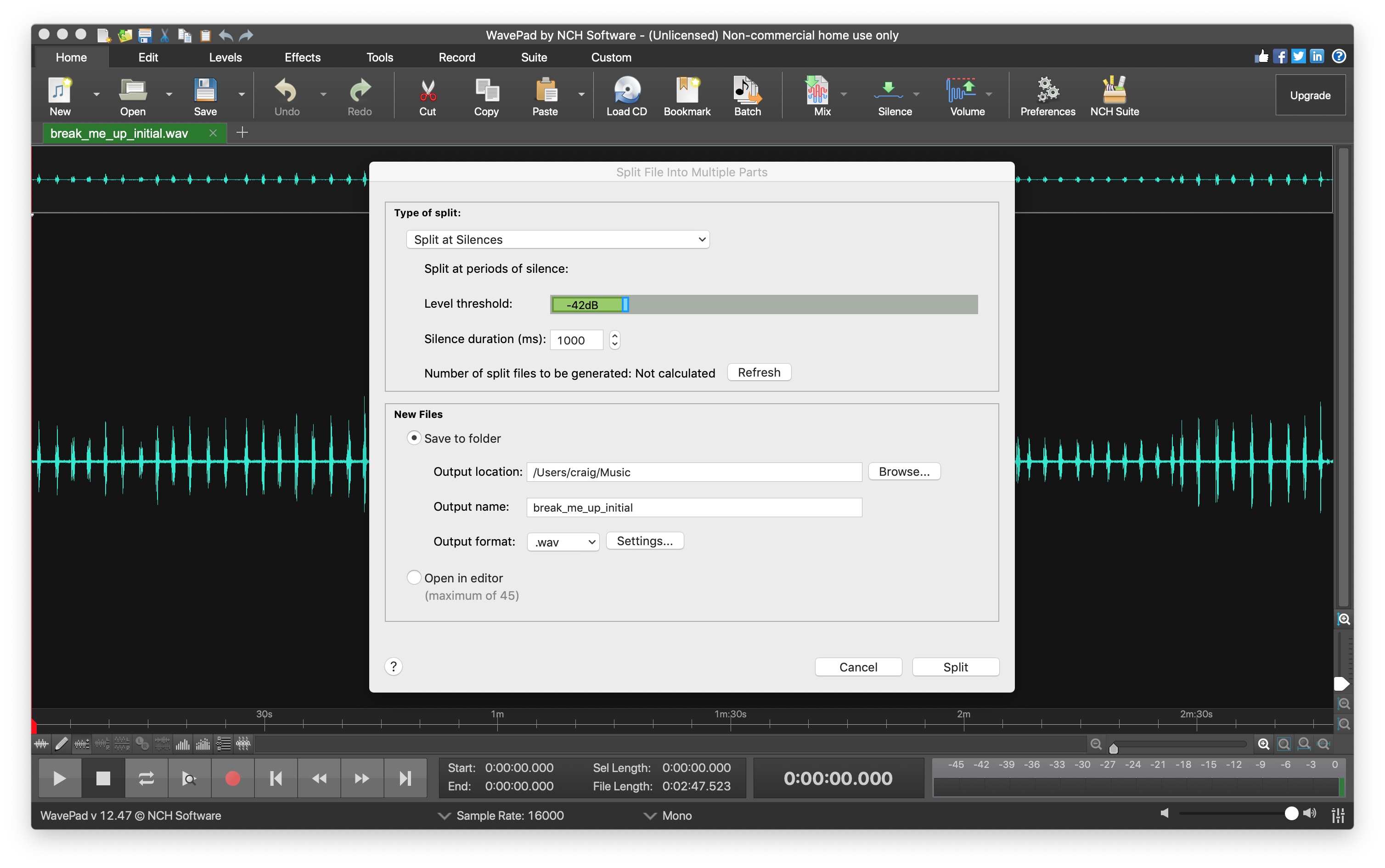
In WavePad, it’s a simple task to open the long file, and then use the Edit -> Split File -> Split at silences command to generate the individual files. It works a charm – and the WavePad is perfectly free for non-commercial use. Using this method, once I dialed in the proper threshold for silences, the program output perfectly-chopped up instances of my wake-word.
I may find that I’m totally wrong about SoX, but at least for me, for the moment, this workflow has saved a lot of time and neatly avoided the issues I was having with precise-collect and SoX.